A Statistical Analysis of Broadway (and Off-Broadway) Musicals
06 05 2014
A few weeks ago, I came across a blog post by Matt Daniels in which he explores the vocabulary usage of various hip hop artists. Being a huge musical theatre fan, that gave me an idea: what would this type of analysis look like if it was applied to musicals? Also, what other questions could be asked about the lyrics and music found on musical soundtracks?
Collecting the data
First, I had to collect data. I had remembered using AllMusicals.com in the past for finding musical theatre lyrics, since they had the cleanest page format and best selection of shows. I used Python to download the HTML and BeautifulSoup to scrape the lyrics for the songs in each show.
Unfortunately, AllMusicals lacked metadata. For each show, I only had the list of song names, and their lyrics. In order to do any analysis of specific lyricists or composers, I would need to crawl another source. Wikipedia seemed to have information about most shows, so I decided to crawl their list of musicals to obtain the Wikipedia titles for each:
import urllib3
category="Category:Broadway_musicals"
s = "http://en.wikipedia.org/w/api.php?action=query&format=json&
list=categorymembers&cmtitle="+category+"&cmlimit=max"
http = urllib3.PoolManager()
response = http.request('GET', s)
response = json.loads(response.data)
# Get all page titles from response
pages = [page["title"] for page in response["query"]["categorymembers"]]
# For each page of the query response, keep collecting page titles
while "query-continue" in response.keys():
s = "http://en.wikipedia.org/w/api.php?action=query&format=json&list=categorymembers&cmtitle="+category+"&cmlimit=max&cmcontinue="+response["query-continue"]["categorymembers"]["cmcontinue"]
response = http.request('GET', s)
response = json.loads(response.data)
pages = pages + [page["title"] for page in response["query"]["categorymembers"]]
pages = [page.encode('ascii', 'ignore') for page in pages]
Now that I had the Wikipedia titles, I decided to crawl DBpedia for metadata. For those of you who aren't familiar with DBpedia, it is essentially a database of Wikipedia infobox data in the form of triples (subject, predicate, object). It is very popular in the Semantic Web community but can also be useful for data mining tasks. The Wikipedia infoboxes can be difficult to scrape, so DBpedia can sometimes be faster for these sorts of tasks.
1. Wikipedia Infobox
Finally, I wanted to get more information about the duration of each track and the artists attributed to each track (if available). I learned that Spotify has an API which allows users to execute searches and obtain information at the track-level. I installed the pyspotify library and used that to access the API.
First, I executed a search for the Wikipedia show title of every show I had collected so far. I computed a similarity score (here lower is better) for each album result based on the similarity between the album result's track names and the actual track names crawled on AllMusicals. If there was at least one acceptable result (in my case I found that anything above .3 was not a good match), I saved the album with the best score.
import spotify
# Execute search query
search = session.search(query)
search = search.load()
album_results = search.albums
# If we find no results, report error
if len(album_results) == 0:
raise StandardError("Error: no search results found.")
scores = []
for album in album_results:
album.load()
# Obtain track list
browser = album.browse().load()
tracks = browser.tracks
# Get lists of candidate album's track names and the actual track names
track_names = [track.name for track in tracks]
target_names = [song["name"] for song in show["songs"]]
# Obtain a similarity score between the two lists
score = search_score(target_names, track_names)
# Save the score
scores.append(score)
# If none of the results have an acceptable score, report an error
if min(scores) > .3:
raise StandardError("Error: no results above threshold")
# Get the Spotify album with the best score
result = album_results[scores.index(min(scores))]
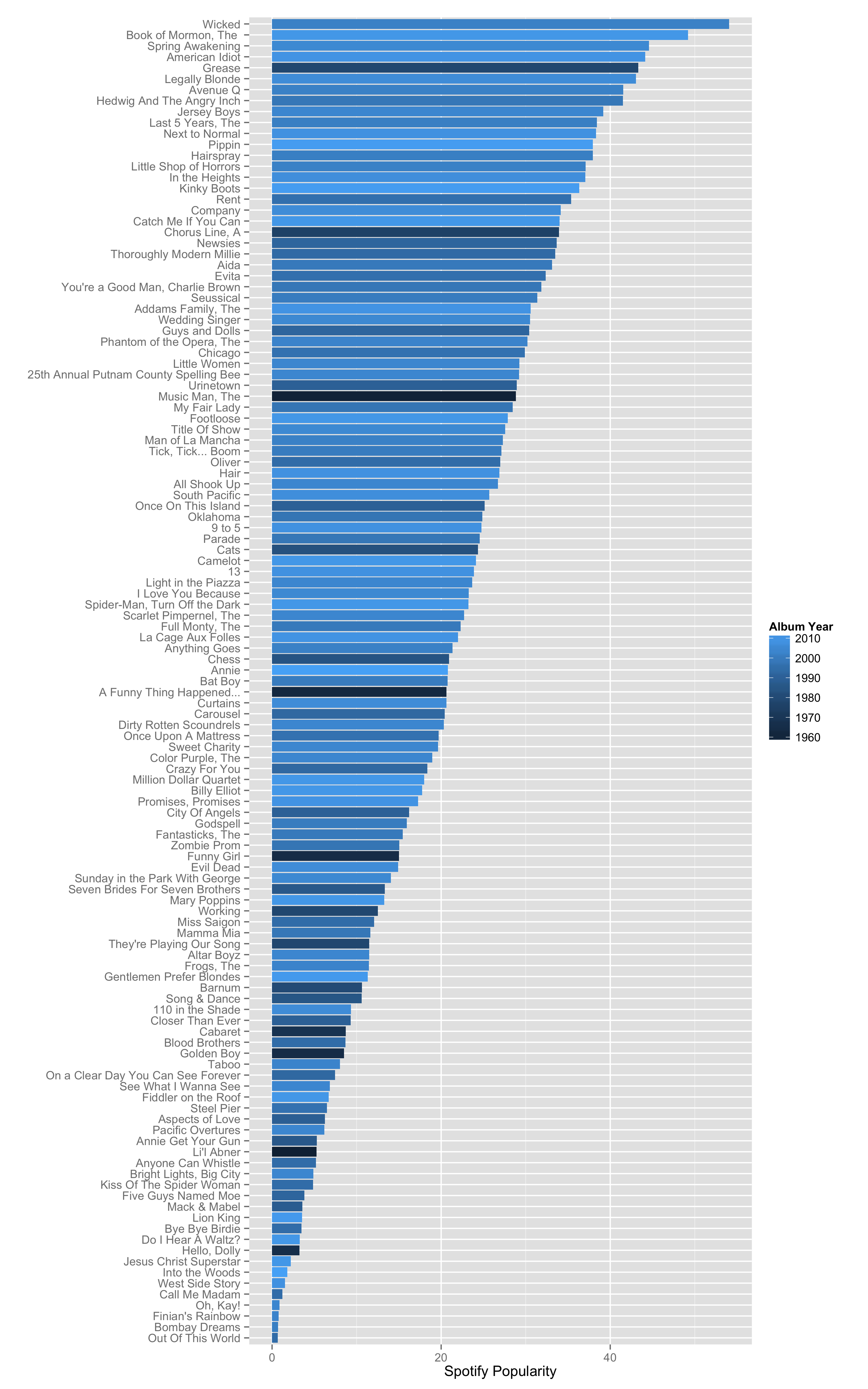
I will be adding to this blog post over the next few days with more details and analysis, but just as a teaser, here is a plot of the most popular musical albums on Spotify, colored based on their album year. I think it's fun to see which shows have stood the test of time.